AI Disregards "Good" Content
The general guidelines for showing up in AI responses are to "be helpful" and "use E-E-A-T."
This is not enough. ChatGPT and other large language models (LLMs) are more concerned with clean, unambiguous, and highly-structured data entities than they are with human-flow writing. Instead of a blog post, they require content that appears to be a trustworthy database entry.
Stop optimizing for human eyes and start optimizing for machine ingestion if you want to win. These three tactical plays are non-negotiable.
1. The RAG-Proofing Content Architecture
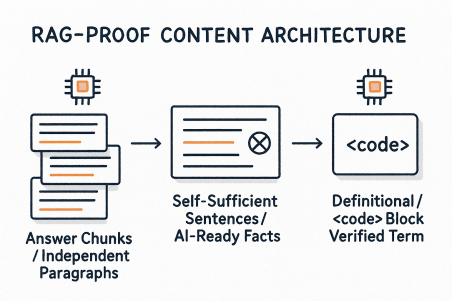
LLMs use a process called Retrieval-Augmented Generation (RAG) to find and "chunk" specific data points. Your content structure must align perfectly with how RAG systems segment information.
The Self-Contained Answer Chunk
RAG systems frequently divide content into discrete, self-contained "chunks" (such as a single paragraph) and pull just that chunk. The AI citation will be unclear or incorrect if your sentence depends on the preceding paragraph for context.
-
The Self-Sufficient Sentence Rule: If a sentence contains a fundamental fact you wish to be cited, you should never begin a paragraph with a pronoun such as "This," "It," or "They." Rather than: "The new widget is revolutionary. It cuts down on processing time by 40%," write: "The Widget-Pro 3000 is a category first, cutting down on processing time by 40%."
-
The Definitional
<code>Block: Avoid using prose to define a proprietary process or a key term. Display it as a stylized block or, better yet, as a markdown code block or an HTML<code>tag. The AI is informed by this structural isolation that the text is a single, validated, and extractable knowledge unit.
LLM seeding is defined as the deliberate production and dissemination of factual, highly structured content intended especially for Large Language Models to use and reference in their generative responses.

Want to see how AI talks about your brand?
Join 500+ companies tracking their AI visibility. Get started in 2 minutes.
Start Free Trial2. The Entity Consensus & Third-Party Seeding
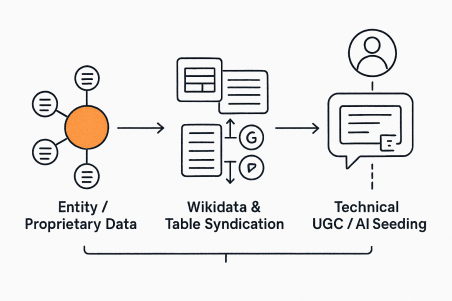
AI models prioritize information that is corroborated across multiple, high-authority sources. They are seeking Entity Consensus—agreement on a fact or definition across trusted domains.
The Wikidata/Review Ecosystem Anchor
Don't just publish your unique data on your blog; plant it in the datasets the AI trusts most.
-
The 'Comparison Table' Syndicate: Create a definitive, comprehensive "Top X Tools" or "A vs. B Comparison" page on your website. Make sure the data is in an HTML table marked up with Product or Review schema. Then, syndicate the core, data-rich table or unique feature list to high-authority review sites (like G2, Capterra, or niche forums). The AI sees the same fact on multiple, highly trusted domains, increasing its confidence score to cite you.
-
Own Your Wikidata Entry: Put effort into creating or improving your unique product, service, or methodology's Wikidata entry. Wikidata is a structured knowledge base that is frequently used as a foundational source for LLM training and RAG.
-
Support Technical UGC (User-Generated Content): Keep an eye on forums such as Reddit and Stack Exchange. When a user asks a very specific question that your product answers, respond to it on your blog using the "self-contained chunk" method, and then post a brief, cited summary into the forum with a link to your definitive source. This creates an "AI-friendly" summary in a well-known, high-ingestion AI feeding ground.
3. The Trust Signal: Moving Past Generic E-E-A-T
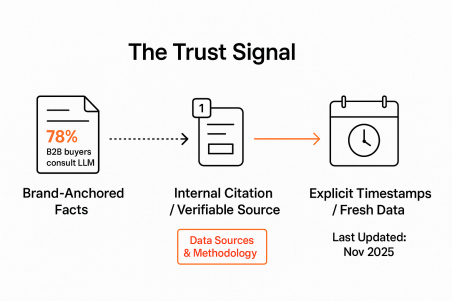
While Expertise, Experience, Authority, and Trust are important, the AI needs Verifiability and Temporal Freshness.
The Citation Footnote Mandate
To convince an LLM your unique data is not a hallucination, you must anchor it with internal, structured proof.
-
The Internal Citation Block: When citing internal or external data, use an internal footnote marker (e.g., [1]) that points to a "Data Sources & Methodology" section at the bottom of the page. This keeps the citation authority on your domain while still proving verifiability, forcing the AI to link the unique fact to your entity.
-
Anchor Facts to Your Brand's Authority: Never use generic data like "Studies show..." Instead, always attribute unique figures to your brand's unique source: "According to the Q4 2025 'Generative Commerce Report' by [Your Brand Name]."
-
Explicit Timestamps: Add a dedicated, highly visible "Last Updated: November 2025" field, preferably marked up with DateModified Schema. LLMs prioritize fresh, current information for RAG, especially for time-sensitive data like statistics, pricing, or regulations.
Conclusion: From Content Marketing to Data Engineering
Making an appearance in ChatGPT is a data-engineering problem, not just a content-writing one. By implementing a RAG-centric architecture, giving entity consensus across trusted platforms priority, and enforcing structured verifiability, you transform your website from a collection of pages into a highly citable knowledge base—which is the only way to be the reliable source that the AI cites without having to pay for an advertisement.

Gilles Praet
Co-founder
Gilles is the Co-founder of Visiblie, helping brands optimize their visibility across AI platforms.